# Via Hugging Face
\
Diversos dels [models](https://langtech-bsc.gitbook.io/aina-kit/models "mention") disponibles a través de la [pàgina Hugging Face del projecte Aina](https://huggingface.co/projecte-aina) es poden utilitzar (a nivell de testeig i prototips) a través de les diferents plataformes que s’ofereixen a Hugging Face.
També s’ha habilitat l’opció de fer entrenaments (*fine tuning*) a la plataforma [SageMaker d’Amazon](https://aws.amazon.com/es/sagemaker/) fent servir el vostre propi compte. En alguns models també és possible fer-hi “AutoTrain".
Podeu revisar la documentació de Hugging Face referent a aquestes funcions per resoldre els dubtes.
### Desplegament de LLM (Text-Generation) a Huggingface Inference Endpoints
{% hint style="info" %}
💡 HuggingFace inference endpoints permet el desplegament de LLM al cloud d'una manera administrada, per tant, l'enginyer no s'ha de preocupar del manteniment i disponibilitat del servei d’infraestructura (auto escalabilitat, disponibilitat, etc.).
Aquesta guia està enfocada a desplegar els models disponibles a Aina Kit a HF Inference Endpoints, també s'inclouen alguns trucs per estalviar costos.
Per tant, és possible que és ometin alguns passos de com crear l’endpoint. Podeu seguir la guia completa disponible a la documentació oficial de Huggingface:
{% endhint %}
**Requisits**
* Un compte/organització de Huggingface amb una targeta crèdit associada o pagament associat amb compte d’AWS via AWS Marketplace
* Podeu configurar el vostre mètode de pagament a
**Passos a seguir per desplegar Flor 6.3B a Inference Endpoints:**
[Obrir el dashboard de Inference endpoints](https://ui.endpoints.huggingface.co/) → **New endpoint**
* Seleccioneu el model **projecte-aina/FLOR-6.3B** o un altre LLM.
* Introduïu un nom per l’endpoint o deixeu-ho per defecte.
* Seleccioneu proveïdor de cloud segons la disponibilitat (**no cal tenir un compte** en el proveïdor de cloud).
* Reviseu la taula de requisits mínims/recomanats del model que heu seleccionat i escolliu el tipus d’instància.
En opcions avançades es recomanen les següents configuracions:
* **Replica autoscaling**: Establir **Min a 0** d’aquesta manera la inferència s'aturarà i no es facturarà el temps que l’endpoint no estigui actiu. Aquesta opció aplica quan l’endpoint no rep cap petició en 15 minuts.
* **Quantization**: En cas de voler aplicar un tipus de quantització, recomanem que seleccioneu Bitsandbytes. Preferiblement, proveu de desplegar el model amb o sense cap quantització per veure quina configuració us és òptima/adient.
* Configureu Max Input Length, Max Batch Prefill Tokens, Max Number of Tokens i Max Batch Total Tokens segons les vostres necessitats.
Preferiblement, les altres opcions no esmentades les hauríeu de deixar per defecte.
Com s’havia esmentat anteriorment, si no requeriu un d’un servei disponible al moment podeu activar l’escalament del servei a 0, per això, seleccioneu l’opció **“After 15 minutes with no activity”.**
En cas de requerir un servei disponible podeu escollir l’opció **“Never automatically scale to zero”**.
Recordeu que també podeu definir el màxim de rèpliques d’escalament automàtic del servei (això és útil per si s’incrementa el nombre de peticions). HF inference endpoints escala i desescala el servei segons les necessitats.
Seleccioneu els tipus de protecció pel vostre endpoint, si el mètode que voleu és “Protected” podeu generar el vostre token a Profile → Settings → [Access tokens](https://huggingface.co/settings/tokens)
Finalment pressioneu sobre "Create endpoint". Assegurar-vos que el model carrega correctament i l'API estigui aixecada correctament (podeu fer servir l'apartat de "Logs").
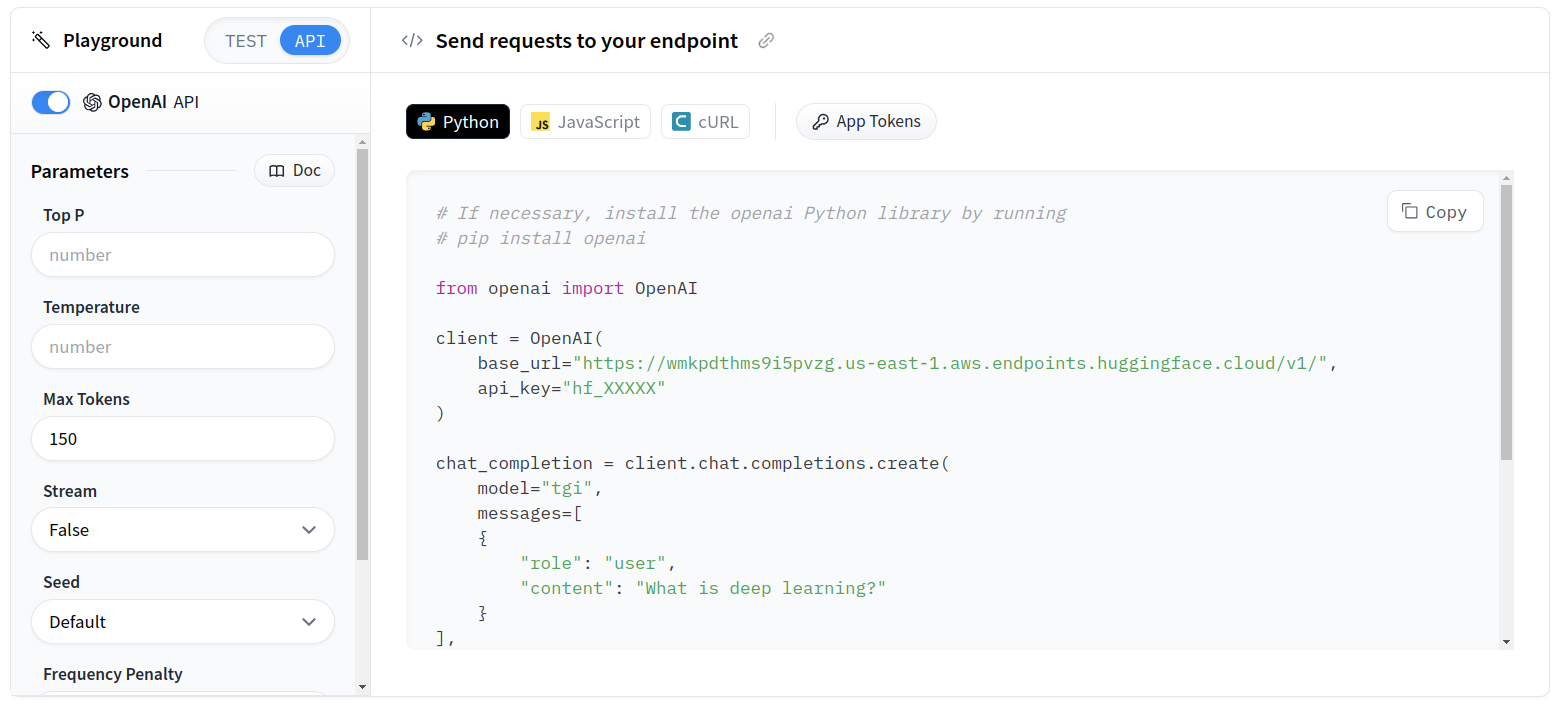
Dins de la pestanya "Overview" també disposareu d'un playground per enviar prompt de test i també instruccions clares per fer crides a l'endpoint via API.
Més Informació d’interès:
* Els endpoints també es poden crear via l'API de Huggingface
* Els endpoints es poden posar en pausa i escalar via l'API de Huggingface endpoints
Documentació de referència: